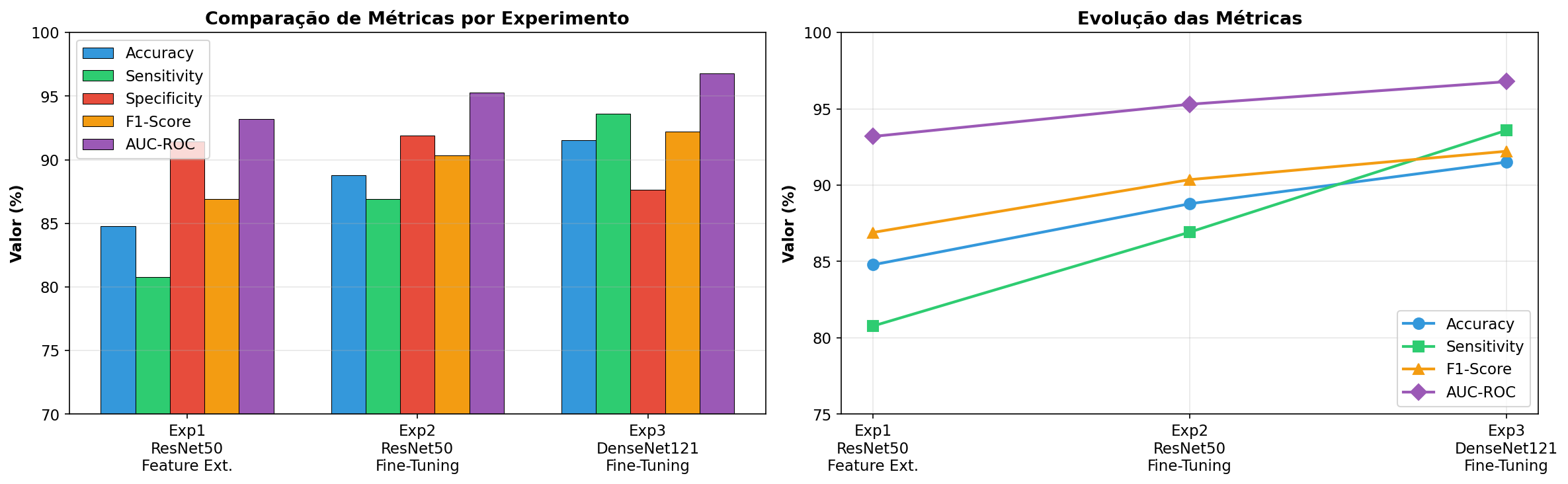
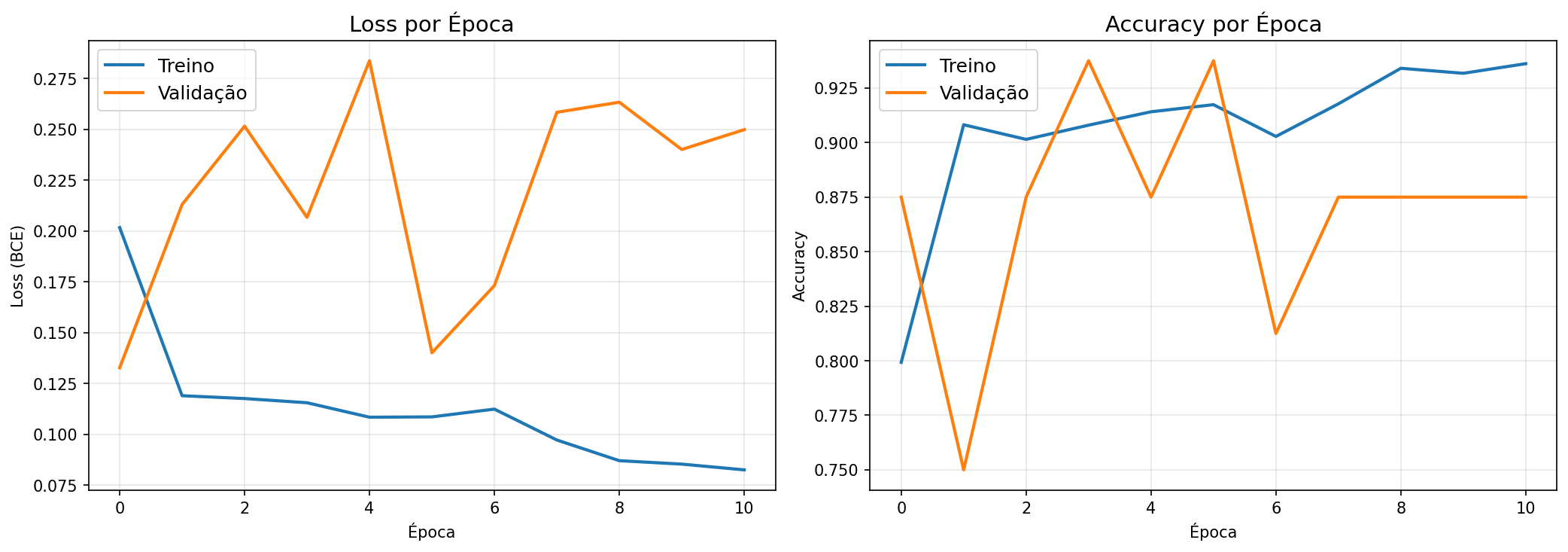
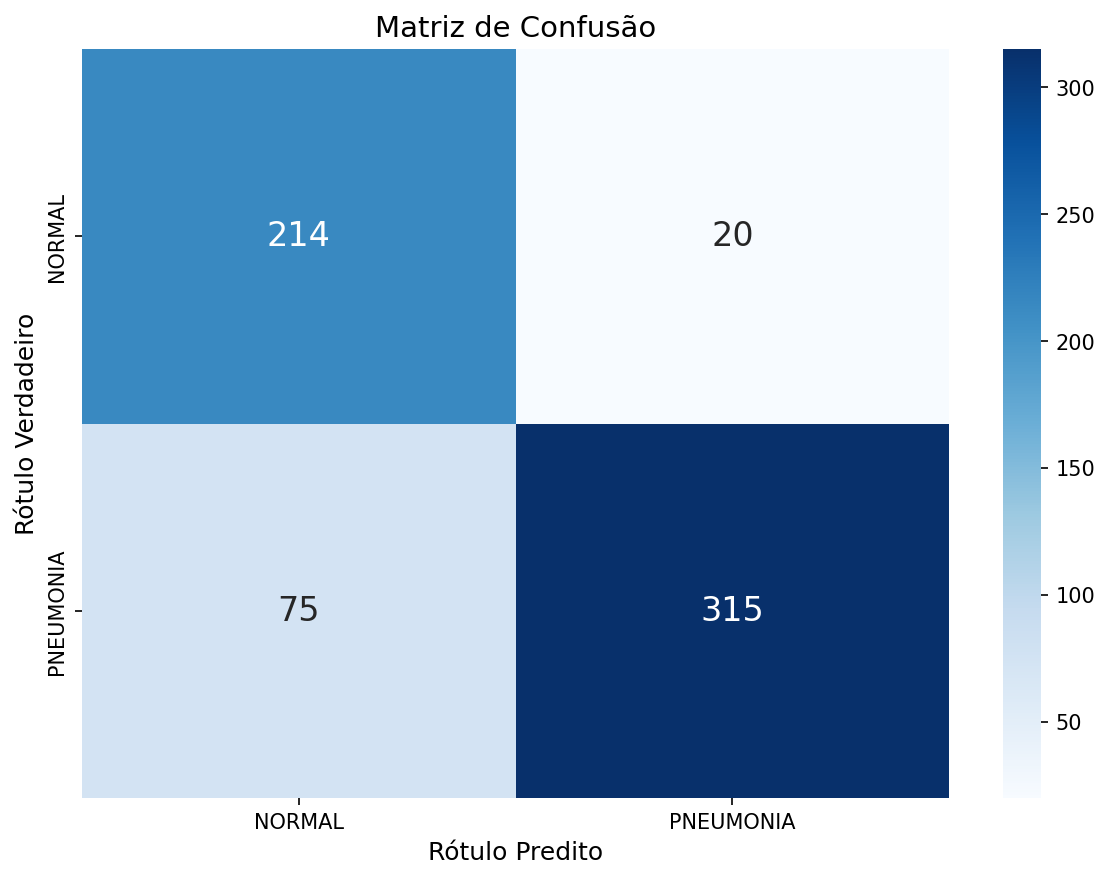
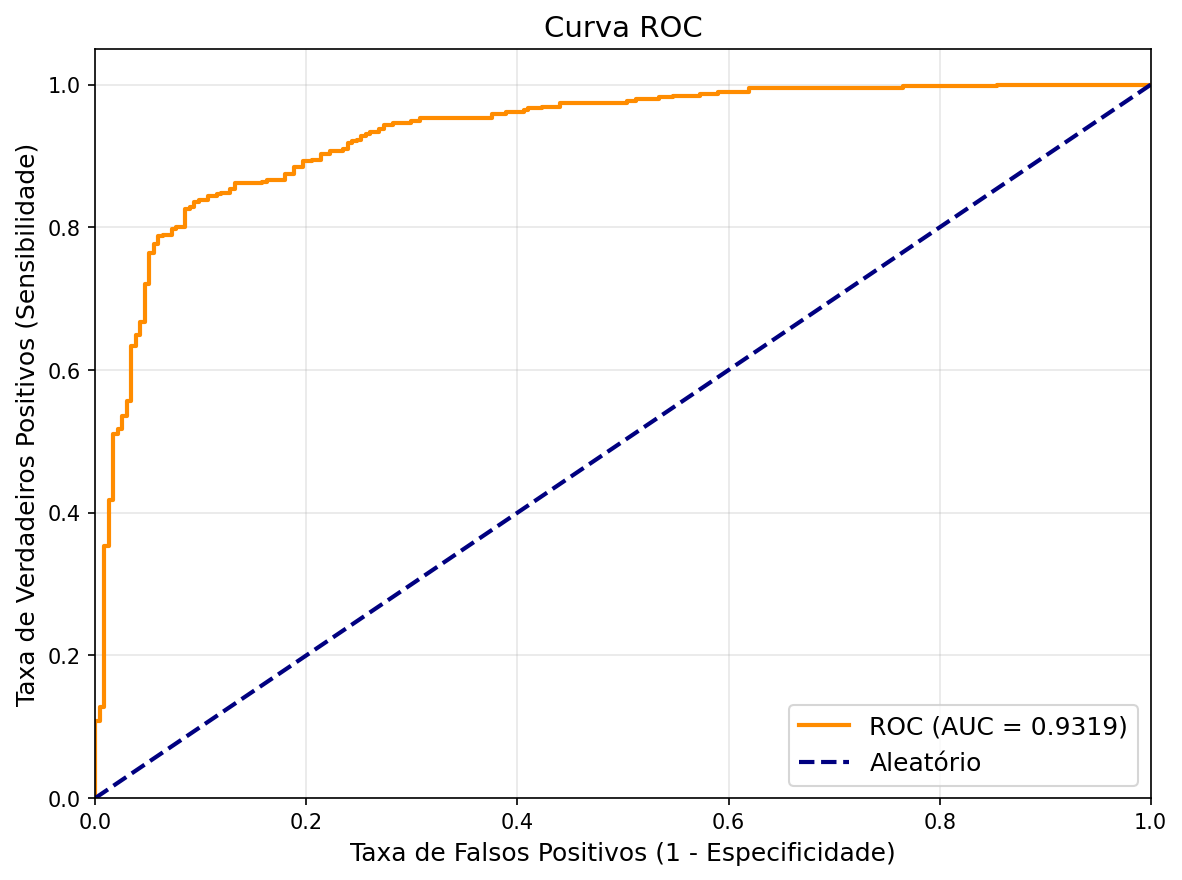
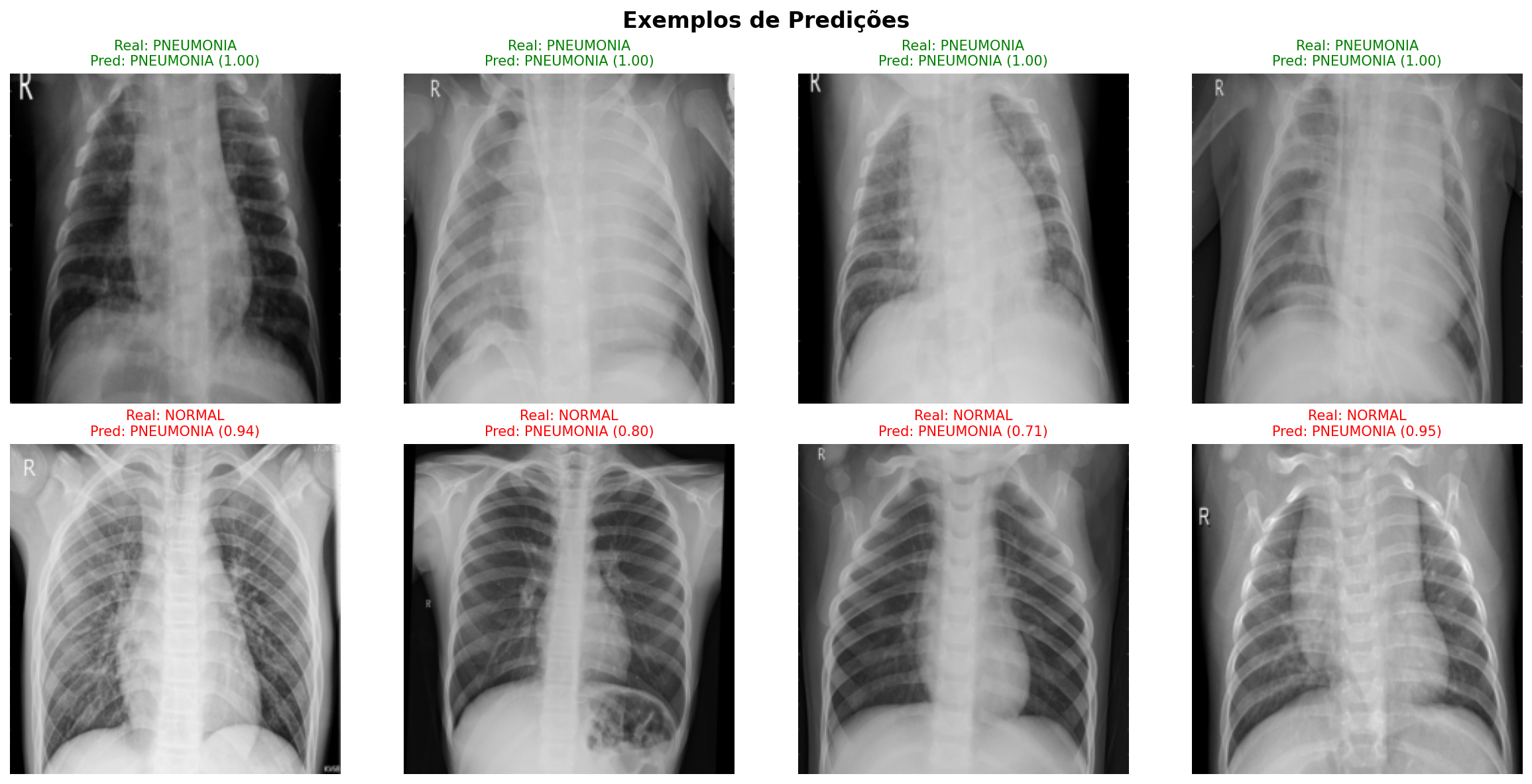
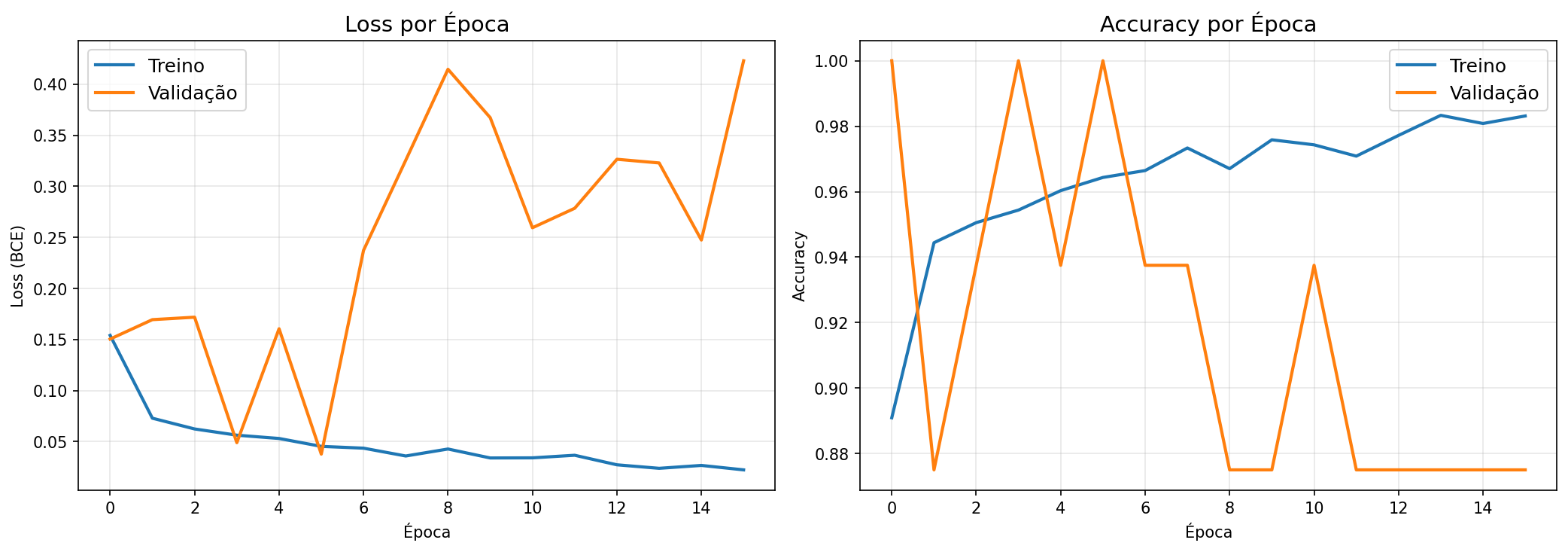
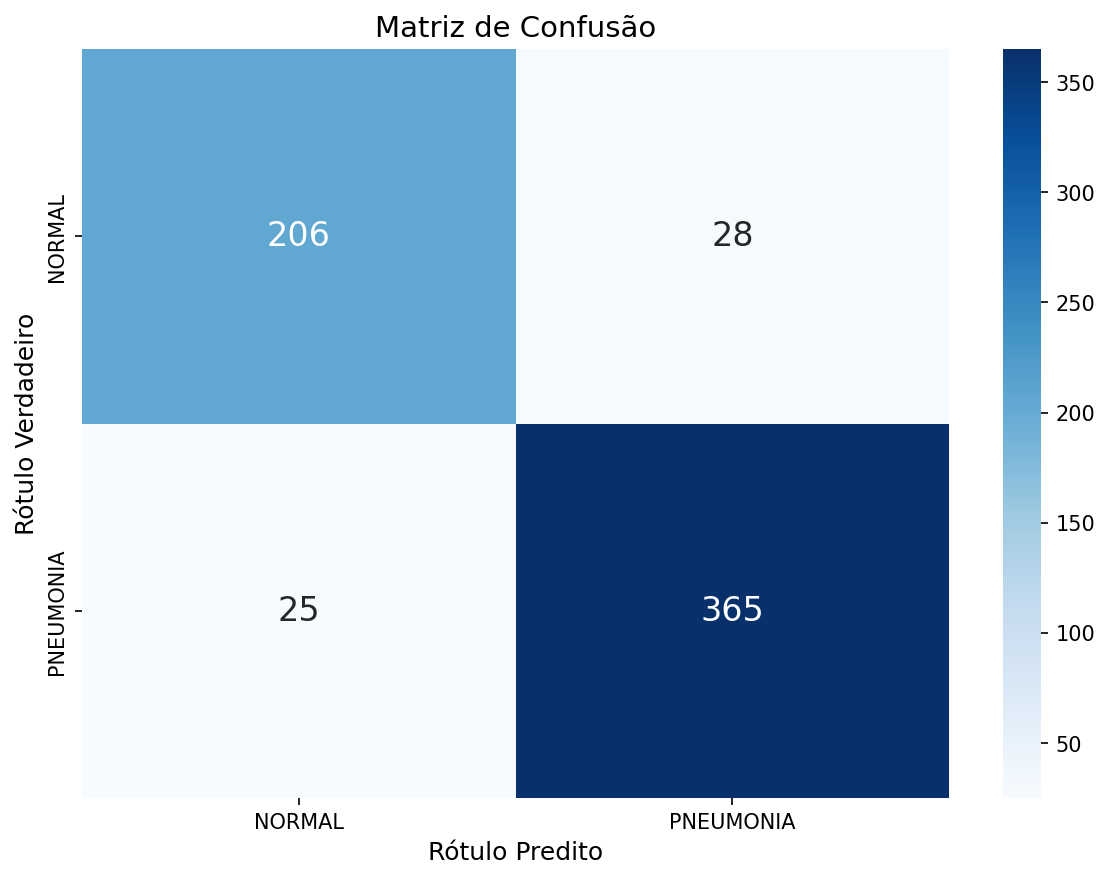
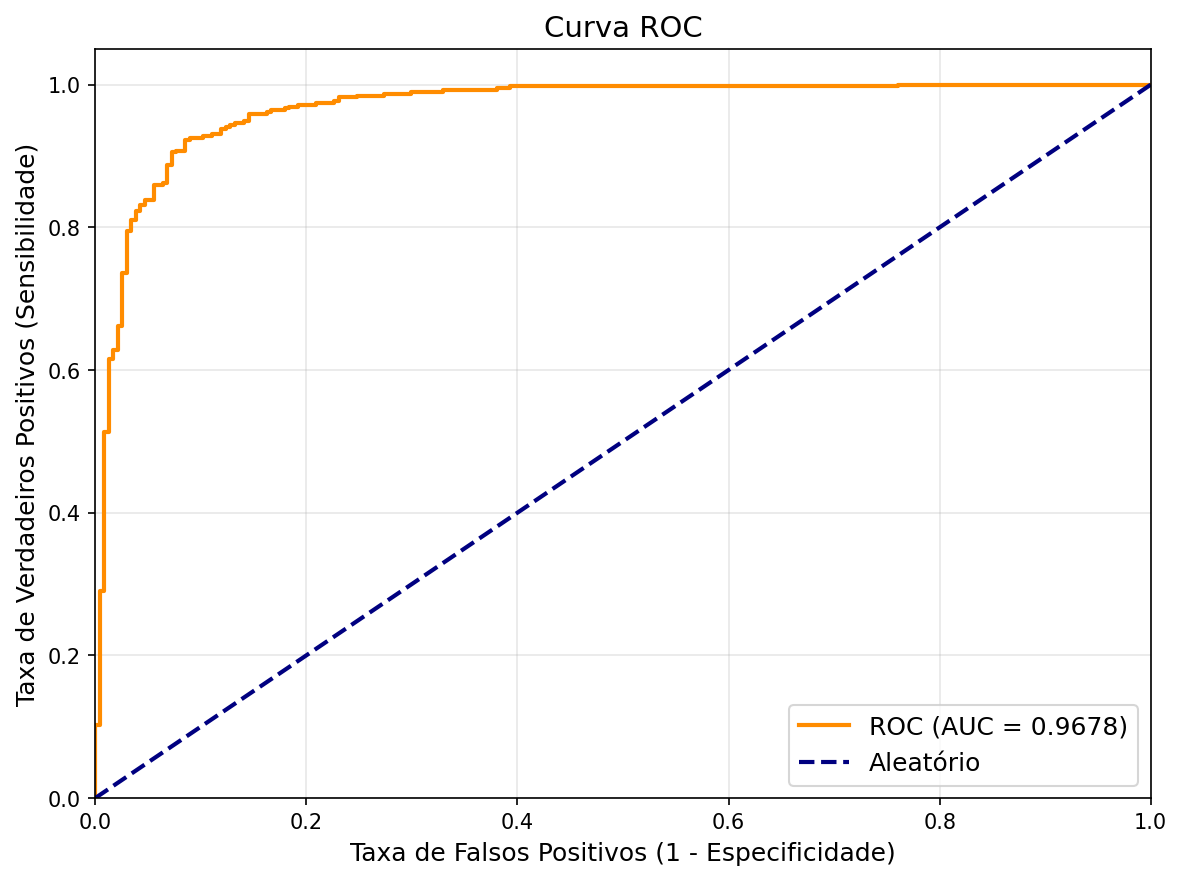
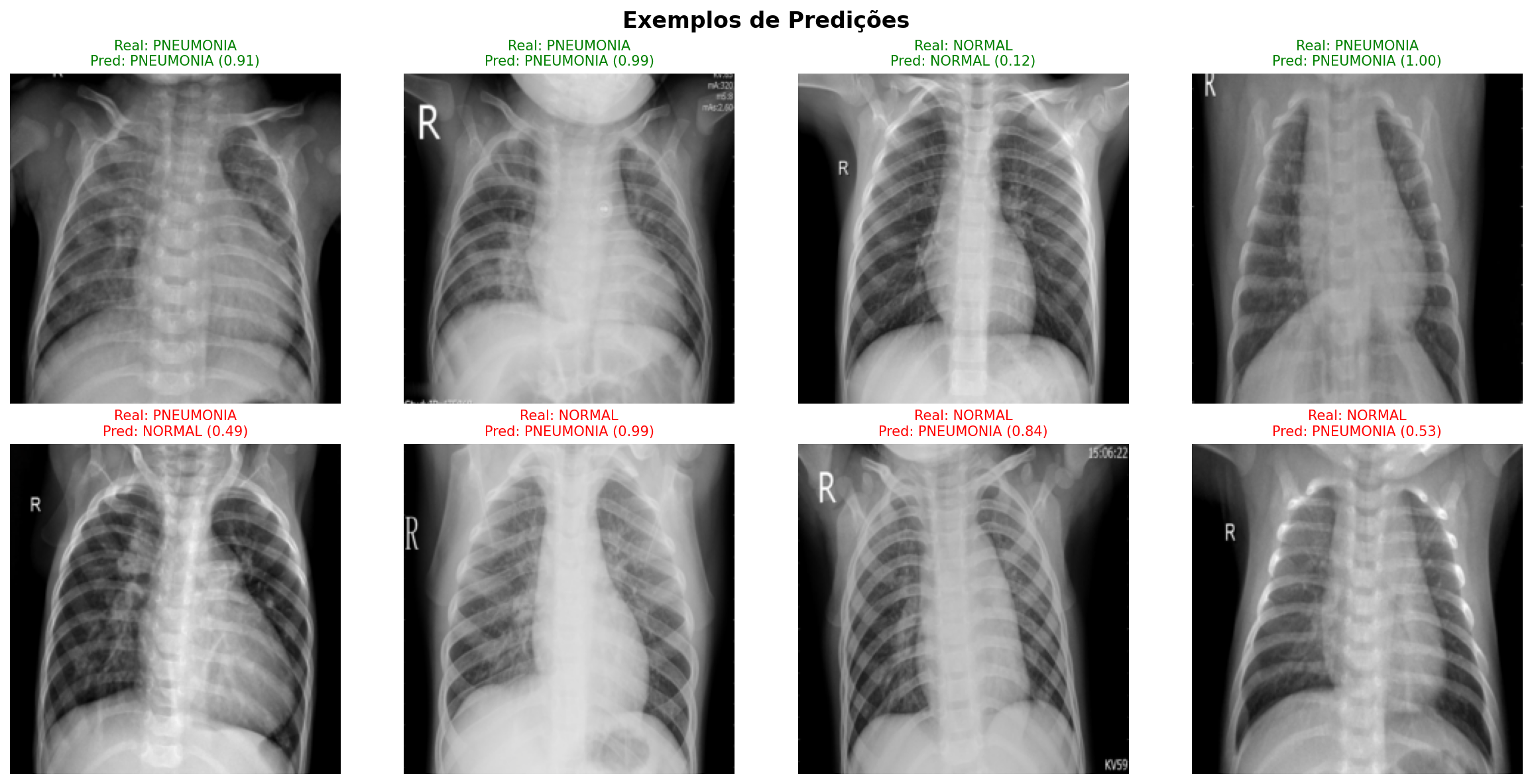
Arquitetura do Classificador
O classificador final substituído nas redes pré-treinadas possui a seguinte arquitetura:
Linear(in_features, 512) → ReLU → Dropout(0.5)
Linear(512, 256) → ReLU → Dropout(0.3)
Linear(256, 1) → (BCEWithLogitsLoss aplica sigmoid)
Técnicas de Treinamento — Funcionamento e Adaptação ao Projeto
As técnicas abaixo foram utilizadas a partir de bibliotecas de terceiros
(PyTorch, torchvision) e adaptadas especificamente para o problema de classificação de pneumonia em
raio-X.
🖼️ Data
Augmentation (torchvision.transforms)
Data Augmentation é uma técnica que aplica
transformações aleatórias nas imagens apenas durante o treino, aumentando
artificialmente a diversidade dos dados sem coletar novas amostras. Reduz overfitting ao impedir
que o modelo memorize os exemplos de treino. Cada transformação foi escolhida com base na
natureza das imagens de raio-X de tórax:
RandomHorizontalFlip (p=0.5)
Espelha
horizontalmente com 50% de probabilidade. Justificativa: a anatomia pulmonar é
aproximadamente simétrica, então um raio-X espelhado ainda representa um pulmão
plausível. Dobra efetivamente o dataset de treino.
RandomRotation
(±15°)
Rotaciona a
imagem em até ±15 graus. Justificativa: pacientes raramente ficam perfeitamente
alinhados durante o exame. Rotações pequenas tornam o modelo robusto a variações de
posicionamento, comuns na prática clínica.
ColorJitter
(brightness/contrast ±0.2)
Varia levemente
brilho e contraste. Justificativa: a intensidade do raio-X varia conforme o equipamento,
tensão do tubo e dose de radiação. O modelo deve ser invariante a essas variações de
aquisição entre diferentes hospitais. Saturação e matiz foram mantidos em 0 pois raio-X
é escala de cinza.
Normalização
ImageNet (mean/std)
Normaliza com
média [0.485, 0.456, 0.406] e desvio [0.229, 0.224, 0.225] — os valores do ImageNet.
Necessária pois os pesos pré-treinados foram ajustados com essa normalização; usá-la
garante que as ativações da rede estejam na mesma escala esperada durante o
pré-treinamento.
📉
BCEWithLogitsLoss com pos_weight (PyTorch)
Binary Cross-Entropy with Logits
Loss é a função de perda padrão para classificação binária. Combina internamente a
função Sigmoid com a Binary Cross-Entropy em uma única operação numericamente estável:
L(x, y) = −[y · log(σ(x)) + (1 − y) · log(1 − σ(x))]
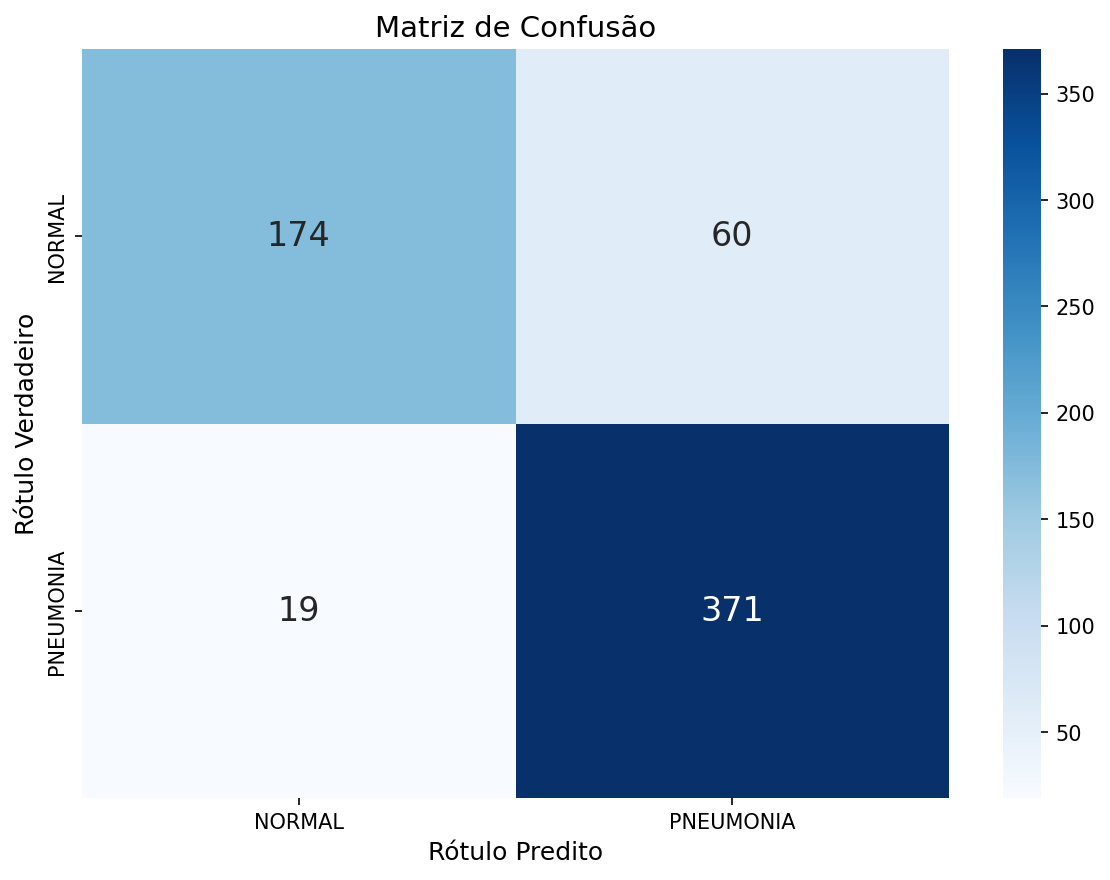
Adaptação ao desbalanceamento —
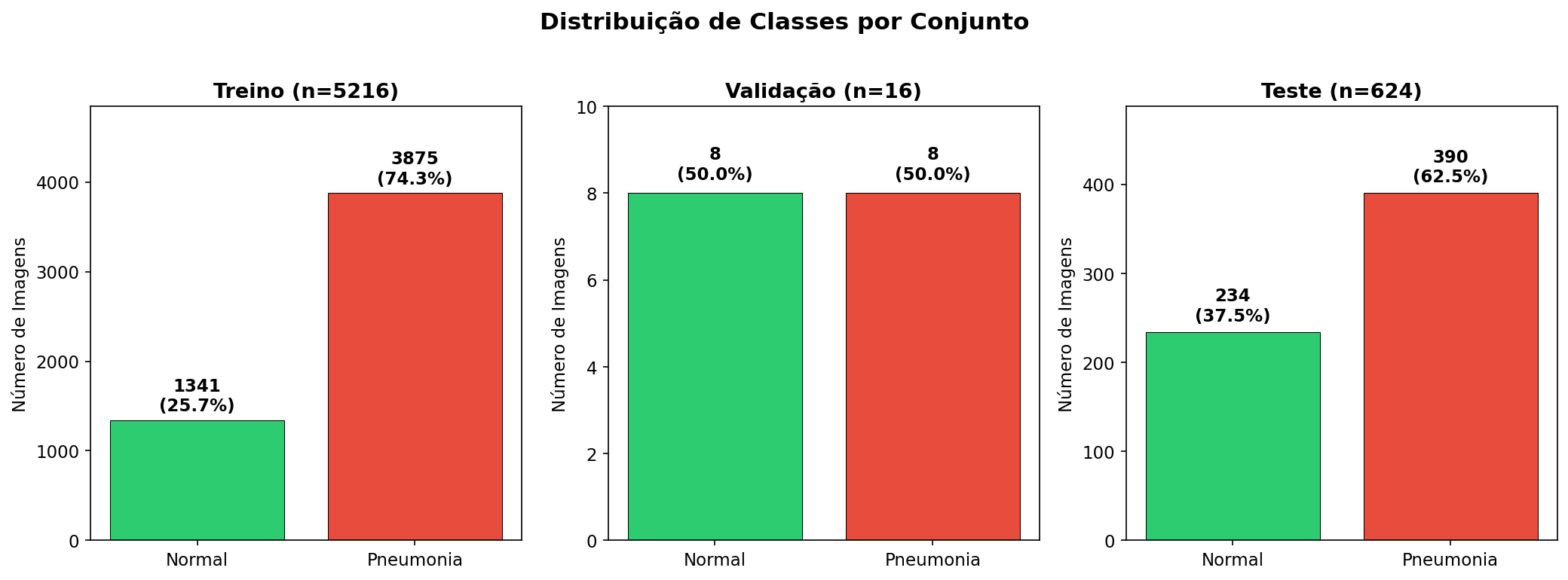
pos_weight: O dataset possui 3.875 casos de Pneumonia para apenas 1.341 Normais
(razão ~2.9:1). Sem correção, o modelo tende a prever sempre "Pneumonia" e ainda assim ter boa
acurácia. O parâmetro pos_weight penaliza mais os erros na classe minoritária:
pos_weight = n_negativos / n_positivos = 1341 / 3875 ≈ 0.346
Valor calculado dinamicamente no código
(compute_class_weights em utils.py) e passado ao critério a cada experimento,
garantindo que cada classe contribua igualmente para o gradiente.
⚙️
Otimizador Adam (PyTorch — Kingma & Ba, 2015)
Adam (Adaptive Moment Estimation) é um
otimizador que mantém taxas de aprendizado adaptativas por parâmetro, combinando os benefícios
do Momentum e do RMSProp. Atualiza os pesos usando estimativas do primeiro momento (média) e
segundo momento (variância não centralizada) dos gradientes:
θ
t = θ
t-1 − α · m̂
t / (√v̂
t + ε)
onde m̂ = média dos
gradientes corrigida; v̂ = variância dos gradientes corrigida
LR = 0.001
Exp 1 (Feature Extraction)
LR =
0.0001
Exp 2 e 3 (Fine-Tuning)
LR menor para não destruir
pesos pré-treinados
Weight Decay =
10⁻⁴
Regularização L2 em todos os experimentos
📊
ReduceLROnPlateau (PyTorch)
Scheduler que reduz automaticamente a taxa de
aprendizado quando uma métrica monitorada para de melhorar. Implementa a estratégia de "diminuir
ao estagnар": se a validation loss não melhora por patience épocas
consecutivas, o LR é multiplicado por um fator de redução.
LRnovo = LRatual × fator (se val_loss não melhora por N
épocas)
Configuração usada neste
projeto: Monitorando val_loss (mode='min'), fator de redução = 0.1 (LR multiplica
por 10%), paciência = 5 épocas, LR mínimo = 10⁻⁷. Isso permite que o modelo "cruze" platôs de
gradiente sem travar em mínimos locais.
🛑 Early
Stopping — Implementação Própria
Early Stopping é uma técnica de regularização
que interrompe o treinamento quando a performance no conjunto de validação para de melhorar,
prevenindo overfitting. A implementação foi desenvolvida do zero na classe
EarlyStopping em utils.py, sem uso de biblioteca externa:
// Lógica implementada (utils.py, linha ~249)
se val_loss não melhorar: contador += 1
se contador ≥ patience (10): interrompe treino
se val_loss melhorar: salva model.state_dict() → best_model.pth
Isso garante que o modelo salvo seja sempre
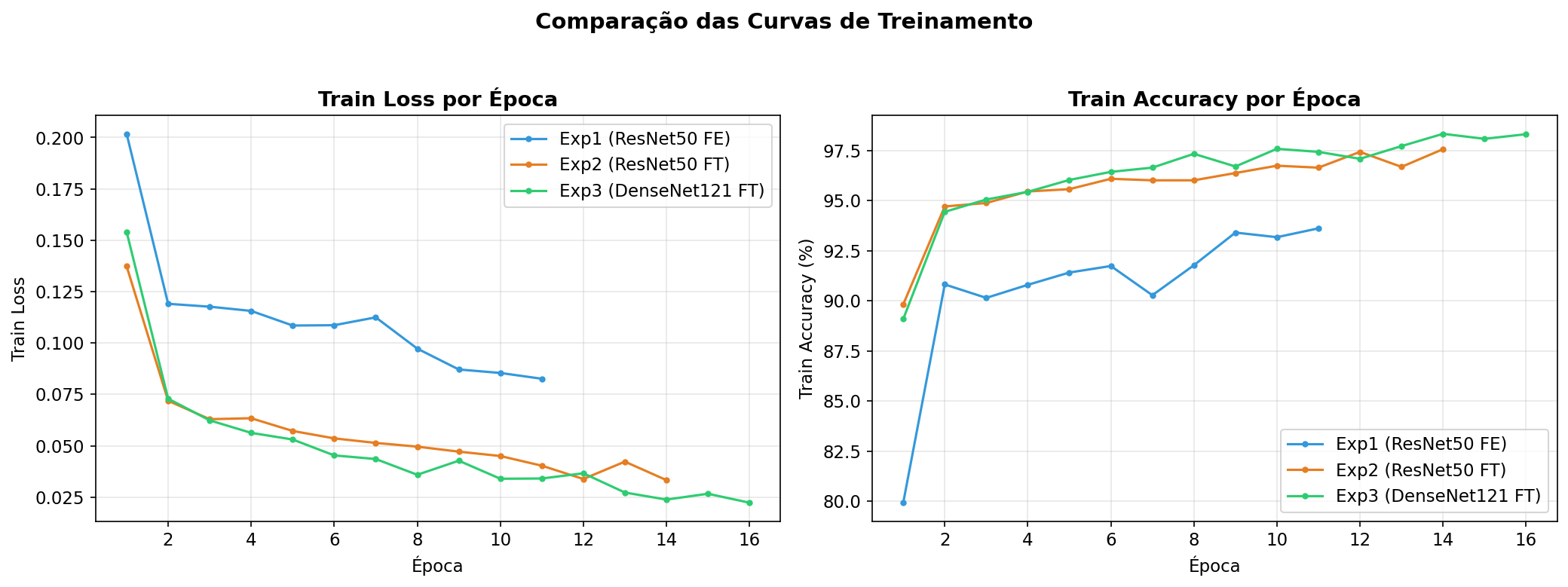
o de melhor performance na validação, não o da última época. Todos os 3
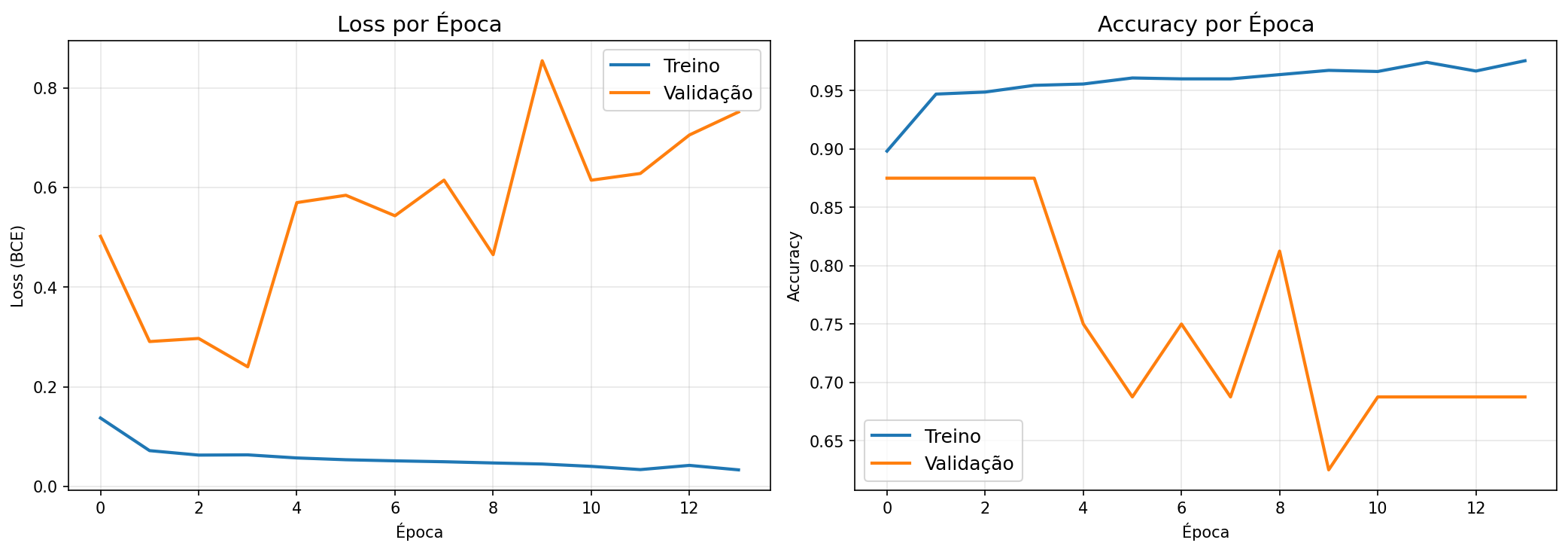
experimentos convergiram antes do limit máximo de épocas (Exp1: 11/30, Exp2: 14/50, Exp3:
16/50).